The Web Conf 2024, Singapore: Trip report

By Thomas Steiner. Written on . Conference Research Work
Background

The Web Conference (formerly known as WWW) is an international conference focused on exploring the current state and the evolution of the Web through the lens of different scientific disciplines, including computing science, social science, economics, and political sciences. It's organized by the Association for Computing Machinery (ACM) Special Interest Group on the Web (SIGWEB) and is held annually in a different location around the world. The 2024 conference took place in Singapore from May 13 to 17. It's attended by 70% academia and 30% industry. Google was a Gold sponsor, together with TikTok.
Conference
Day 1
Online trust day
Keynote I: Factuality Challenges in the Era of Large Language Models
Speaker: Dr. Preslav Nakov, Professor and Department Chair of NLP, MBZUAI
Fact-checking the output of LLMs: Decompose the output of an LLM into its individual claims, decide which are check-worthy, check one-by-one:
Detecting LLM-generated texts:
Arabic LLM:
Jais Arabic LLM, see the prompt instructions.
Audience question: Why don't we use LLMs for what they are good for: working with language like reformulating or summarizing, but not asking them to come up with facts. — We probably could, but hallucination problems there as well.
Keynote II: Building Trust and Safety on Facebook
Speaker: Lluís Garcia Pueyo, Director of Engineering, Meta
For many languages there isn't enough actually harmful labeled content, so models are trained on artificially oversampled labeled examples.
Facebook posts ranking formula: probability you like something, probability you share something, probability you hide something. Like, comment, and send are not good signals for bad experiences. Hiding, reporting from the three dot overflow menu are.
Future challenges with LLMs:
Meta folks are organizing the Integrity Workshop series.
The Dynamics of (Not) Unfollowing Misinformation Spreaders
Collected health misinformation URLs and tweets tagged by PolitiFact. Found users who share this content on Twitter. Denoted these users misinformation spreaders. Also pulled the followers of spreaders. They found that misinformation ties are rarely severed, with unfollowing rates of 0.52% per month. Users are 31% more likely to unfollow non-misinformation spreaders than they are to unfollow misinformation spreaders. Reciprocity, initial exposure, and ideology are the most important factors for predicting unfollowing.
Web4All (Sponsored by Google)
Touchpad Mapper: Exploring Non-Visual Touchpad Interactions for Screen-Reader Users
Touchpad Mapper: maps the position of objects in images to the touchpad area, so when the screen reader user moves their finger over the touchpad, the position of the finger is taken into account for announcing the image contents.
- Touchpad Mapper, requires a backend app to extract the exact physical coordinates of the finger on the touchpad.
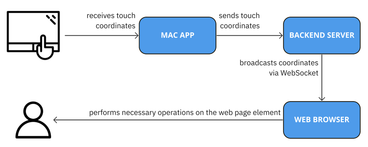
Beyond Facts: 4th International Workshop on Computational Methods for Online Discourse Analysis
Leveraging Large Language Models to Detect Influence Campaigns on Social Media
They used an LLM to determine if, based on user metadata and network structures, a user is part of an organized information campaign. Their model was trained with Russian troll tweets. These Moderation Research datasets are available freely from the X Transparency Center.
Escaping the Echo Chamber: The Quest for Normative News Recommender Systems by Abraham Bernstein
Looked at news recommendations. Interesting datasets: MovieLens, Book-Crossing.
Towards Fact-check Summarization Leveraging on Argumentation Elements tied to Entity Graphs
Used PolitiFact as ground truth and compared GTP4 vs. Custom GPT to see if the models could come up with similar results.
Detection Distortions in Science Reporting by Isabelle Augenstein
Looked at how journalists cover scientific research. Scientific findings frequently undergo subtle distortions when reported, e.g., with regard to certainty, generality, and causality.
- Sentence BERT: framework to compute sentence / text embeddings for more than 100 languages. These embeddings can then be compared, e.g. with cosine-similarity, to find sentences with a similar meaning.
Day 2
Web4All (https://www.w4a.info/2024/)
Keynote Speech: Liddy Nevile "Accessibility?"
(Liddy Nevile is the mother of one of the organizers, Charles McCathieNevile, aka. Chaals.) Her son went to university at 10 to learn Logo, so she would learn it, too. Got to know folks at MIT. One of them was Tim Berners-Lee. Worked with Mosaic folks and how blind kids would use it. Concerned about inappropriate content. Founded Platform for Internet Content Selection (PICS) W3C group, which created a numbering system to classify content. Opened the way for what people at the time thought of as curation of content. Was well received by the adult industry. Eric Miller wondered why, if PICS worked, couldn't embedded descriptions, ideally structured, also work? Created "metadata" catalog, which ended up becoming Dublin Core. Published An Introduction to the Resource Description Framework.
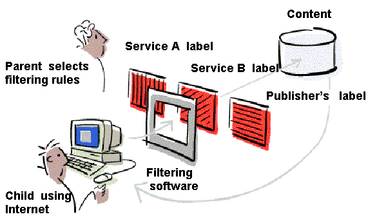
Platform for Internet Content Selection (PICS, source) W3C used a grant to set up the Web Accessibility Initiative (WAI). Worked on how to encode resources so they would be accessible to users. How could a blind person find out where the cursor is? How could flickering content be avoided? WAI brought people together to learn about making accessible websites. Some countries converted WAI into national laws. Could compliance be put into the resource, just like PICS? Different countries do things differently. Australia doesn't prosecute people for not complying with Web Content Accessibility Guidelines (WCAG). Worked on making math books accessible with MathML. Inclusion (make something accessible just in case) or accessibility (make something accessible just in time). Worked on structured accessibility data. Jutta Treviranus worked on Access4Al: "Whether using a public workstation, or engaging in an on-line learning environment, computer systems should fit the individual preferences and requirements of the user, especially if the user requires an alternative access system. An international effort is underway to create a common specification for expressing personal preferences for all systems affecting the user interface and content retrieval". Took accessibility description work further with schema.org in the form of accessibilitySummary. Now there's ISO/IEC 4932 (Core Accessibility Metadata). Looking forward to seeing accessibility services working with AI at last doing what we dreamed of so many years ago. If accessibility is an opt-in, it needs to be made sure that the data isn't abused. Good privacy fields help, it's about the people, everyone occasionally needs accessibility features. (The speaker said they were very thankful to Google for the schema.org work.)
Decoding the Privacy Policies of Assistive Technologies
They looked at the privacy policies of various assistive technologies companies. It's not great; some of them collect data about sexual orientation.
QualState: Finding Website States for Accessibility Evaluation
Web accessibility evaluation engine called QualState for automatically testing the accessibility of web apps. QualState loads a page, performs actions. Identifies events on page. Clicks links, buttons, and submits forms based on the DOM tree. Ignores some nodes, but needs a full DOM tree to see which states the page was already in.
A Universal Web Accessibility Feedback Form: A Participatory Design Study
Hypothesis: companies don't get accessibility complaints because the feedback forms are inaccessible. Placement of the feedback link reduces or creates entry barriers. Add an introduction paragraph. Describe each step clearly. Make sure constraints (multiple choice checkboxes, radio buttons, etc.) are clearly explained, and don't rely purely on technical error message handling. Allow contact information to be added optionally. The form should provide details on where exactly on the website a problem occurred. Allow for system settings to be shared and the used assistive technology. Make their tool available on GitHub: human-centered-systems-lab/a11y-feedback.
Accessibility and AI
Can AI coding assistants produce accessible UI code? Yes, when explicitly instructed to do so. They are not reliable and subject to hallucinations. Dark mode button worked fine. Image had mixed Japanese/English alt text. Can AI coding assistants eliminate the need for developer accessibility awareness? Accessibility features are not applied consistently. There might be states that get missed. Empty alt texts are hard to catch, since it looks intended. More benchmarks are needed. Fine-tuning models for accessible UI. AI powered DevTools can help, too. Copilot doesn't make any claims about the accessibility of its created code.
Evaluating the Effectiveness of STEM Images Captioning
Teaches university students Web development. Asks them to take the #NoMouse Challenge. Split their group in two groups: one was trained on image accessibility, one wasn't. Correctness (does the description accurately describe what the image depicts) vs. usefulness (does the description accurately describe the conveyed meaning) of describing images. Created AI image descriptions with IDEFICS (demo). Students were asked to evaluate human-generated vs. AI-generated descriptions. Describing STEM images (like diagrams describing photosynthesis) generally is hard. In all cases, humans performed better. The AI had more problems with STEM images. Planning to compare other AI engines. Also thinking about ways to improve the prompt engineering (e.g., "Describe this detailed scientific diagram in a way that the description is useful to a blind user").
Making Accessible Movies Easily: An Intelligent Tool for Authoring and Integrating Audio Descriptions to Movies
Steps for creating movie audio descriptions (AD): read existing subtitles with OCR, identify speech gaps based on missing subtitles, create scene description texts with VideoChat or VideoLLaMa, then use ChatGPT to merge the subtitles and the scene description. The final step is to run text to audio and audio mixing. Created an app called EasyAD that incorporates all these steps. Quality was evaluated as being good, but speed was still slow, feedback also suggested more languages than Chinese should be supported.

Towards Effective Communication of AI-Based Decisions in Assistive Tools: Conveying Confidence and Doubt to People with Visual Impairments at Accelerated Speech
Screen reader users typically comprehend speech 3 times faster than sighted users. Speeded up voices lose some of the emotions of speech like confidence or doubt. Up to a factor of 1.5 to 2 this effect isn't noticeable, at faster speeds it's noticeable and research is required to reintroduce these emotions.
Welcome reception
The welcome reception took place in the Tipsy Unicorn.


Day 3
Keynote#1: Challenges toward AGI and its impact to [sic] the Web
Speaker: Jie Tang This keynote was about how they created the Chinese ChatGPT called ChatGLM (智谱清言), which means "clear words of wisdom".
Web4Good
CapAlign: Improving Cross Modal Alignment via Informative Captioning for Harmful Meme Detection
The authors prompt a large language model (ChatGPT) to ask informative questions to a pre-trained vision-language model (BLIP-2) and use the dialogs to generate a high-quality image caption. To align the generated caption with the textual content of a meme, they use an LLM with instructions to generate informative captions of the meme and then prepend it with the attributes of the visual content of a meme to a prompt-based LLM for prediction. (I would love to see this run on top of Memegen.) [Paper]

Panel Discussion on LLM Impact on the Web
Panelists:
- Panel Chair:
- Andrew Tomkins, Research Scientist, Google
- Panelists:
- Jon Kleinberg, Cornell University
- Yoelle Maarek, Chief Researcher, Technology Innovation Institute
- Jie Tang, Tsinghua University
Questions:
Do we expect websites to have LLM-based front-ends?
- Jie thinks it's quite possible. Each website may have an agent that could also interact with other websites' agents.
- Yoelle thinks that if the content of websites is generated by LLMs and LLMs train themselves on the content they created, this may lead to a rich get richer symptom and all LLMs learn the same. Maybe more diverse LLMs can help rather than one dominating one. Hallucinations are a big problem, and they will continue to be. People need the feeling that the information comes from somewhere, to have sources. We need to be careful not to take this feeling away.
- The most popular app on the Web is search. Search puts itself between the page and the searcher. If search doesn't lead to traffic to pages, there's no incentive to create content.
Websites don't need to expose APIs anymore, agents can just talk to websites using natural language. Will this cause specialized search engines to arise? Do we expect one central agent to rule them all?
- Yoelle says before common Web search engines, there was a federated search engine, but it died. Strongly believing in RAG, you need special agents to surface hidden content.
- Jon states it's an old question, special agents like for flight search. You could take special agents and hide them under one common interface. It's mostly a UI question.
- Jie says we have a network of webpages, and later Linked Data. Now AI to answer questions. We could have linked AI to answer special questions.
The Web is special. Someone has gone through the work of, for example, collecting great spots to visit at a place. We would love for this person to keep the benefits. We can do so through advertising. Now the model is changing. Why would people keep creating content under these circumstances? What are possible models for this to work in the future?
- Jon says the Web has always been powered by altruism. Search isn't always about finding the answer, but also about exploring the landscape. People want to hear different takes on a question. LLMs will not just be used to find one answer. If there's economic value created. Mashups is a 2005 concept, we mashed up Google Maps with stuff.
- Yoelle states most websites are automatically created. It's like AirBnB, it's business, not regular people renting out a spare room. If you have specialized RAG-supported LLMs, you have a transaction when hidden content is being found. This isn't the Open Web, maybe it has already disappeared. Economic value could be protected like this.
- Jie isn't sure about this. People only want to consume, they don't necessarily search for something concrete, like TikTok or Douyin.
- Yoelle really wants to disagree. We want serendipity, I love this journey of searching. It's something I must have to earn.
- Jon talks about the economic model. If you're a standup comedian, you start imitating others, and eventually you develop your own style. That's LLMs. You don't owe the comedians you took inspiration from early on.
Audience question by Natasha Noy: I want to broaden this. If we have a highly curated extra layer, it hides this personal layer. We need to discuss this layer.
- Jon says this could be something like an LLM giving out "Likes", or Google Scholar citation counts. Could this be self-prophesying, so people create content only to be cited by LLMs.
Want to talk about privacy and safety. But before that, I want to talk about crawling. It's a massive business. Crawlers asking for access to content could look different than regular users, they already do. Could there be a third class of LLM traffic to websites?
- Yoelle sees the point. People don't protect their websites too much, like with robots.txt, because they know they get traffic back. Now with LLMs it's different. They don't get the value back. It's costly for providers to crawl, Azure, Google, AWS, they make a lot of money off LLM crawlers. We need to think about protocols to support this.
- Jie thinks in the future this depends, if in the future the Web will interact with human beings, if the Web itself is a personal assistant, the Web will change. Not sure how.
- Jon thinks this question is orthogonal to the question of LLMs. We already have alerts and notifications like has the flight price changed, has an article been published on a topic. This is a pilot case for what LLMs could do in a general manner.
Audience question: One of the issues now is who owns the content creator? Google etc. make profit from profiling users. Would we all come to a conference to listen to bot-written papers? When we lose trust in the reflective power of an LLM, who's going to pay for this technology? Is it either you, or my personal information? Will this model work in the future?
- Jie isn't sure about the economic aspect. AI is still occupied with improving its performance. The trust still needs to be earned.
- Yoelle means people won't use AI for trivial things they can do themselves. Reasoning examples we see today are trivial, because the AI is still learning. In the early days of the Web it was authority through PageRank and clicks that brought you value as a creator. Research may be needed to explore if we can somehow give back to creators, I hope it will come naturally. We can also think as creators, what information do we want to make accessible to LLMs.
- Jon asks what's the value we're adding. If we're angry at an LLM, what can I add? Wolfram Alpha now just solves math problems which a hundred years ago you could publish a math paper about.
Audience question: The age of information abundance. In the past, there was information scarcity. For example, you needed to travel to different countries to get information. Now it's the opposite, you have way too much information. Generative AI makes this a lot worse, it creates so much information.
- Yoelle thinks the question is funny. LLMs are good at finding hidden information. But you don't know if it's a hallucination. You don't have the context, so you can't easily verify. The world now isn't deterministic. We're all computer scientists, we're used to determinism. Now it's not the one truth. You live in a fuzzy world now. Maybe we all become computer artists. Scared by the uncertainty. I want proof, I lost this.
- Jon disagrees a bit. You visit a doctor, and each doctor you visit tells you something different. Indeterminism existed before. It's a fascinating tension. Huge fan of the abundance question, wrote papers about this. In the early 1970ies, there was a book about information abundance. Abundance is consuming human attention.
Let's touch on trust and safety. There's privacy questions, there's government standpoint questions, there's questions on where LLMs should be hosted. Finance has concerns about data safety. Can you share thoughts about what's the biggest risk right now?
- Jie thinks all this is very important. Technology is super important. AI will self-improve and self-reflect. We could have built a common model to check the quality of models. If AIs in the future will be smarter about this, this would be great.
- Yoelle says it's super important to have many open source LLMs. We need diversity. You could come back to different models, even if they are biased. For many sensitive topics, you can bring models in-house trained on your data, even with lower general quality.
- Jon means powerful tools will reflect society, including its biases. We rely on LLMs as to make decisions.
History of the Web #1
Viola, Pei Wei, and the Fights for Interactive Media

Interesting historical reference: MediaView: a general multimedia digital publication system.
Digital Democracy at Crossroads: A Meta-Analysis of Web and AI Influence on Global Elections
They looked at papers from the past until today that looked at elections. Suggestions for generative AI companies to tackle AI disinformation: Implement watermarking and strict verification, regulate AI chatbots, mark AI-generated content as such. Government should require politics-related material to be marked specially if AI was involved. Educate users to identify AI-generated content. Fake news isn't new, but the scale is way different now. [Paper]
History in Making: Political Campaigns in the Era of Artificial Intelligence-Generated Content
Historically, we had user-generated content. Now we have AI-generated content. It's the year of the elections, in almost 60 countries, covering half of the Earth's population. Political campaigns make use of AI. Huma/real life person impersonating makes caller bots possible. Ashley caller bot in the US. AI-generated deepfake makes campaigning from prison possible. Also malicious deepfakes. ChatGPT is known to be left-leaning in the US. Governments crack down on services and tools to create and spread AI-generated content and limit access to user data. [Paper]
Me, the Web and Digital Accessibility
Fun anecdote: IE showed the alt attribute like a tooltip. The author is the official translator of the WCAG standard for Portuguese and got into accessibility when he was made aware that Brazil's government required websites to be accessible. [Paper]
From Files to Streams: Revisiting Web History and Exploring Potentials for Future Prospects
Users love fast web content and there's an economic value in performance. 1991: all content text-based and delivered from one server. Now all types of content are delivered via CDN. Cites HTTP Archive stats on website size and First Contentful Paint. FCP didn't improve. HTTP was FTP inspired. TCP handshake cost needed to be paid. Less files meant faster loading time. Keep-alive allows reusing TCP connections. HTTP/2 and HTTP/3 reduced the overhead, no more line-blocking, multiplexing and streams, 0-RTT. Server delivery was improved. Client side lacked. JS (1995), CSS (1996), DOM (1998). Bundling as a solution to make less requests. Browserify (2013), then Webpack. Webpack's popularity peaked just when HTTP/2 was introduced. A solution (bundling) for a problem that doesn't exist anymore. Erwin Hofman: "Bundling is an antipattern in HTTP/2". Render-blocking as a major annoyance, can use dead code elimination and critical CSS identification. Can stream content over HTTP/2 or /3. Sees research challenge in automatic content usage detection and ordering of JavaScript. They stream Web content via WebSocket (demo). [Paper]
Posters
Automating Website Registration for Studying GDPR Compliance

They used a headless browser to sign up to websites and then see if they had GDPR violations. [Paper]
Breaking the Trilemma of Privacy, Utility, Efficiency via Controllable Machine Unlearning
TIL about the concept of Machine Unlearning. The work explains how parts of a model's training data can be removed without having to retrain the entire model. [Paper]
A Worldwide View on the Reachability of Encrypted DNS Services

They compare different privacy-preserving ways of how DNS can work over encrypted data and how they affect global reachability. [Paper]
Uncovering the Hidden Data Costs of Mobile YouTube Video Ads
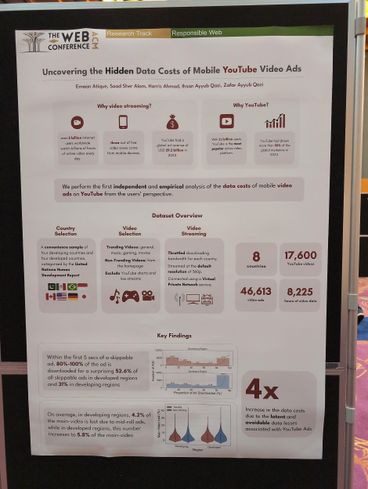
They look at wasted bandwidth from YouTube ads. Apparently we preload quite eagerly, even if most ads are skipped as soon as possible. [Paper]
Day 4
Keynote#2: Revisiting the Behavioral Foundations of User Modeling Algorithms
Speaker: Jon Kleinberg Algorithms as partners, GPT should stand for General Purpose Technology. In contrast to algorithms as creators of environments, like when they curate social media experiences. When consuming a linear feed, after each item the user has the chance to quit or continue scrolling. cThe algorithms are tuned to bring you chips because you know you crave them, while at the same time you also know that you should be having a salad. Sees AI as a semi-autonomous vehicle.
Systems #2
A Multifaceted Look at Starlink Performance
M-Lab Tests makes open-source data about Internet speed tests available. Measurement Lab is led by teams based at Code for Science & Society; Google, Inc; and supported by partners around the world. Internally, the Google team responsible is called Open Internet Measurement. Median latencies for Starlink is ~40–50ms, while mobile networks are ~30ms. NA and EU (regions with dense ground stations concentration) enjoy the best coverage. Very few locations where Starlink outperforms cellular. Closeness to the ground station determines latency a lot. [Paper]
PASS: Predictive Auto-Scaling System for Large-scale Enterprise Web Applications
Paper that looks at the Web app scaling of Meituan, a Chinese shopping platform for locally found consumer products and retail services including entertainment, dining, delivery, travel, and other services. Uses app's recent performance data to predict upcoming load. Offline model (looks at historical data) doesn't have information about spontaneous spikes, online model (looks at just passed data) has a slight lag. Uses hybrid auto-scaling by combining predictive scaling with reactive scaling. [Paper]
FusionRender: Harnessing WebGPU's Power for Enhanced Graphics Performance on Web Browsers
Smaller language translation overhead. Omits runtime error checks. Recucs data communication between GPU and CPU by using pre-packed configuration. They compared WebGL vs. WebGPU. Three.js, Babylon.js, PlayCanvas, and Orillusion. WebGPU is slower(!) on all frameworks. Frameworks render objects separately , leading to redundant transmission. Merged rendering leads to reduced transmission. How can it be determined which objects can be merged? Graphics rendering configurations. They introduce FusionRender. Input: user-defined configurations, output: WebGPU. Joins objects with identical signatures. Uses a hash map, objects are grouped based on their hash. Implemented a prototype for Three.js, tested on MacBook Pro, ThinkPad X1, and Pixel 6 with Chrome and Firefox. FusionRender shows improvements between ~29% and ~120% with synthetic data, about ~30% with real world data. (Code: qqyzk/FusionRender) [Paper]

QUIC is not Quick Enough over Fast Internet
The paper examines QUIC's performance over high-speed networks. They find that over fast Internet, the UDP+QUIC+HTTP/3 stack suffers a data rate reduction of up to 45.2% compared to the TCP+TLS+HTTP/2 counterpart. This performance gap between QUIC and HTTP/2 grows as the underlying bandwidth increases. The root cause is high receiver-side processing overhead, in particular, excessive data packets and QUIC's user-space ACKs. QUIC perceives much more packets than HTTP/2. In Chromium, much more netif_receive_skb calls are invoked for QUIC. The issue is observed on CLI data transfer clients and browsers (Chrome, Edge, Firefox, Opera), on different hosts (desktop, mobile), and over diverse networks (wired broadband, cellular). Ruled out server software, UDP/TCP protocols, HTTP syntax, TLS encryption, client OS, etc. as reasons. [Paper]
History of the Web #2
Toward Making Opaque Web Content More Accessible: Accessibility From Adobe Flash to Canvas-Rendered Apps
Revisiting 30 years of the Network Time Protocol
Network Time Protocol (NTP) has a hierarchical structure that delivers the time, the stratum 0 server has the most accurate time and passes it on to lower levels. NASA has proposed the Interplanetary Internet. Korea Pathfinder Lunar Orbiter played K-pop from the Web. SpaceX and Blue Origin look at Mars Internet. The Proximity-1 Interleaved Time Synchronization (PITS) protocol looks at how time synchronization could work in space. [Paper]
History of the Semantic Web
A walk down memory lane of the Semantic Web with Jim Hendler. Started with the Scientific American article in roughly 2000. In 2005, started moving from reasoning to linking data. 2010 was the year of Web 3.0, the dawn of semantic search. 2014 Google Sem Webbers: R.V. Guha, Dan Brickley, Denny Vrandecic, Natasha Noy, Chris Welty. Guha in 2014: > 20% of pages included structured data. In 2016 Peter Norvig mentioned >60%. Facebook created Open Graph in 2011. IBM Watson in 2017. Facebook's Graph API made the Knowledge Graph concept more well-known. 44% of pages now use schema.org markup. Wikidata as a free editable knowledge base. The semantic web sort of won, but where are the intelligent agents? AI is getting there, but they are not directly using semantic web technologies.
Verso: A web browser that plays old world blues to build new world hope
A browser called Verso by Daniel Thompson-Yvetot, the creator of the Tauri apps, a framework that uses the system's WebView to ship desktop apps. Tauri uses WebView2 on Windows, WKWewbView on macOS, and webkitgtk on Linux. WebView2 is based on Chromium, which has a good update frequency. WKWebView means some people are stuck on old macOS. WebView W3C effort is slow and won't change things meaningfully. Thought about using the Servo engine. Collaborated with Igalia. Was at Mozilla, now hosted by the Linux Foundation. Tauri folks maintain HTML5ever, used by Servo, Tauri, and Vercel. Engine is based on Servo, and a CLI for headless integration. Deep local language integration for local translation and reader mode transformation. Default incognito profile management mode. Provides a WebView, too. Shards identities, storage, sign-in. Next steps: close early funding round, set up non-profit organization at Commons Conservancy, don't sell search, convince Next Generation Internet (NGI) EU framework to accept the project. They want to launch in summer, coming to this conference was the first step. (Nightly builds)

Day 5
Keynote#4: AI deepfakes on the Web: the 'wicked' challenges for AI ethics, law and technology
Speaker: Jeannie Marie Paterson The word deepfake is a combination of deep learning and fake. Can be used for fun or in movies (e.g., Princess Leia in Star Wars). Can be used for malicious purposes, like Elon Musk deepfake-generated get-rich-quick scams or scammers to fake family members' voices. Romance fakes with face swapping. Deepfaked synthetic porn affecting many K-pop stars. Political deepfakes can affect elections. The liars dividend: people start questioning actual images and calling them deepfake. Responses to deepfakes:
Law: Can get active via transparency requirements, consumer regulators, criminal offenses, online safety. OECD principles of ethical AI.
Education: Look for errors in images and videos, but early signals like blinking patterns have been improved by technology.
Tech: Enforce voluntary guardrails to not create terrorist material, pornography,… Release detection tools, but they often only work on the companies' own AI products. Industry has introduced an official Content Credentials Icon (C2PA).
Participants in the initiative:

Digital watermarks, but it's a cat and mouse game. Watermarks might not survive screenshots or photos of AI-generated photos.
Resource
Ducho 2.0: Towards a More Up-to-Date Unified Framework for the Extraction of Multimodal Features in Recommendation
Multimodal recommender system that integrates with deep learning frameworks like TensorFlow, HuggingFace, or PyTorch. (Demo) [Paper]
The Web Data Commons Schema.org Table Corpora
There are many table corpora, typically used to evaluate ML systems. The corpora use different schemata and formats. Introducing schema.org table corpora to bridge the gap. Use the Common Crawl corpus. Group by host (for example imdb.com) and class. Remove sparse entities and poor annotations. The resulting tables can contain nested entities, for example, the actor type. Needs flattening. Tables and meta statistics files are available for download. Used for table annotation benchmarks, for Q&A datasets, entity matching (based on unique identifiers, like telephone numbers), or as a source for training data. [Paper]
Tel2Veh: Fusion of Telecom Data and Vehicle Flow to Predict Camera-Free Traffic via a Spatio-Temporal Framework
Objective is to apply telecom data to improve traffic flow. Crossing telecom data with vision-based camera data. Make a dataset available with the crossed data. Based on this data, train a predictor using the vision-based data as the groundtruth. System can be used for traffic flow monitoring and traffic optimization. [Paper]
An Open Platform for Quality Measures in a Linked Data Index
Finding a good dataset is a challenge. How can the quality be measured? Need defined quality measures, Propose IndeGx, builds an index of public SPARQL endpoints. Used to compare FAIRness (Findable, Accessible, Interoperable, Reusable) and accountability (traceability, transparency, trust). For dataset creators, quality matters. [Paper]
CompMix: A Benchmark for Heterogeneous Question Answering
Heterogenous question answering systems where the answers come from different sources, like text or tables. CompMix is a dataset of questions and answers. Covers comparatives, superlatives, ad-hoc, count, ordinal questions, etc. Used generative LLMs and other methods to see if they could answer the questions. None of the systems were able to answer 50% or more of the questions, which means the questions dataset is really challenging. Ideally a system should ground the data in a source and make the answer traceable. [Paper]
SE-PQA: Personalized Community Question Answering
Working on personalization in information retrieval. Used StackExchange community questions and answers, tags, and user profile metadata. Trained different models on the dataset. Personalization based on tags improved the quality. [Paper]
Can LLM Substitute Human Labeling? A Case Study of Fine-grained Chinese Address Entity Recognition Dataset for UAV Delivery
Drone delivery systems in China use named entity recognition to convert raw addresses into precise locations using large language models. Needs specifically trained Chinese dataset. Released CNER-UAV dataset. Contains lots of "in the building" or "in the unit complex" or even "in the room" address refinements. Tested with different models and evaluated precision and recall. ChatGLM (the Chinese ChatGPT) performs poorly, GPT compares fine, but struggles with room and other address annotations. [Paper]
Graphameleon: Relational Learning and Anomaly Detection on Web Navigation Traces Captured as Knowledge Graphs
Graphameleon is a browser extension to capture web navigation. Motivations like tracking one's carbon footprint of a browsing session. Has a macro mode that captures the request/response traffic and micro mode that also captures mouse clicks. Use the UCO ontology. Creates a knowledge graph and a 3D graph visualization. Tracks website complexity with and without Firefox strict or standard tracking prevention on. Another use case is to detect attacks like XSS. [Paper]
